- Published on
Redis Key SCAN guide
- Authors

- Name
- liinen
Background
Redis는 싱글스레드를 바탕으로 하는 데이터베이스입니다. 싱글스레드로서 여러 장점이 존재하지만, 주의해야할 사항도 수반됩니다.
그 중 하나로, 특정 명령어가 오랜 시간 수행되며 스레드를 점유할 경우에 서비스에 장애가 발생할 수 있다는 점이 있습니다.
모든 key를 한번에 탐색하여 보여주는 'keys' 명령어는 편리할 수는 있으나, 이 key를 모두 수집하는 데에 시간이 오래 걸리게 됩니다.
즉, 이 명령어를 사용한다면 서비스의 일시 중단에 대한 위험성이 있기 때문에 가급적 사용하지 않아야 합니다.
특정 key를 탐색하고 싶을 때에는 유사한 역할을 수행하는 'scan' 명령어를 사용하는 것을 권장합니다.
redis 2.8 버전에 추가된 명령어인 'scan'은, 일정 batch만큼씩 탐색하는 방식으로 구현되어 있어 스레드를 점유하는 상태는 일어나지 않습니다.
다만 아직 다수의 redis 사용자가 key를 스캔하는 방식에 대해서 익숙하지 않기 때문에 redis key scan guide 를 작성하게 되었습니다.
Redis SCAN
기본적으로 SCAN 명령어는 'cursor'와 'count' 개념이 적용된 iterative한 탐색 방식입니다.
일정량의 count(default 10) 만큼을 batch로 하여, 해당되는 수치만큼의 key를 scan합니다.
자료구조 중 'linked list'를 생각하면 조금 더 이해하기 쉽습니다. (Redis 는 실제로 내부에서 Linked list가 사용됩니다.)
pointer를 따라가며 스캔하고, 다음 스캔의 경우 어느 pointer(cursor)부터 실행하면 되는지 알려주는 방식입니다.
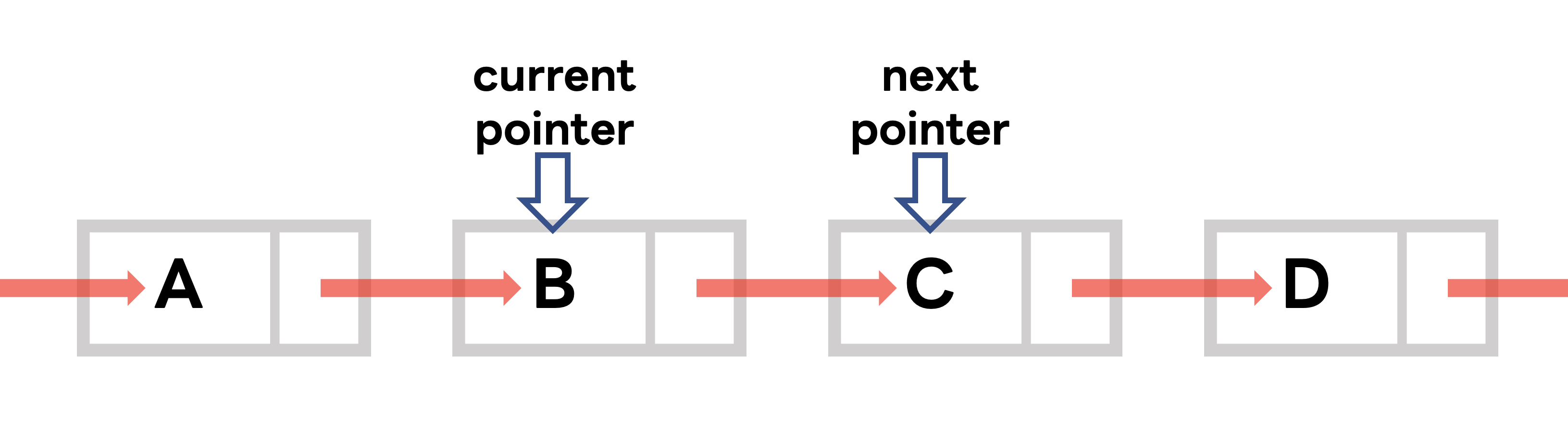
scan 명령어는 두 개의 output을 가지는데, '다음 스캔을 시작할 cursor'와, 'count 갯수만큼의 key' 입니다.
이렇게 습득한 '다음 cursor 값'을 이용해 iterative하게 cursor scan을 진행하여, 모든 key를 습득할 수 있습니다.
redis-cli scan (terminal, interpreter mode)
SCAN cursor [COUNT count] [MATCH pattern]
터미널에서 입력하는 것과, interpreter mode에서 입력하는 방법 두 가지가 존재합니다.
# terminal
> redis-cli -p {port} SCAN 0 MATCH {pattern} COUNT {count}
# redis-cli interpreter
> SCAN 0 MATCH {pattern} COUNT {count}cursor (required)
default count는 10이지만, 항상 10개를 리턴하지 않고 처리 시간을 고려하여 리턴합니다.
예시 코드에서도 scan 0의 경우 count를 별도로 지정하지 않았음에도 11개의 key를 리턴한 것을 확인할 수 있습니다.
127.0.0.1:6379> scan 0
1) "57344"
2) 1) "b163919"
2) "e71056"
3) "e51232"
4) "b182485"
5) "c20095"
6) "c5283"
7) "b31525"
8) "f176318"
9) "b157308"
10) "f51547"
11) "e35182"
127.0.0.1:6379> scan 57344
1) "28672"
2) 1) "b103245"
2) "c101358"
3) "d187664"
4) "f178990"
5) "b162088"
6) "f68844"
7) "b3964"
8) "d84456"
9) "a77798"
10) "a105771"
127.0.0.1:6379>COUNT count (optional, NOT recommended in PROD)
앞서 언급되었던 batch size인 count는 기본적으로 10 이지만, count 옵션을 통해 변경할 수 있습니다.
count를 늘릴 경우, 한 번에 조회하는 key의 갯수가 증가하여 더욱 빠른 처리 속도를 보여줍니다.
다만 해당되는 count가 커질 수록 기존의 'keys' 명령어와 동일한 역할을 수행하게 되므로, 꼭 주의해서 사용해야 합니다.
테스트 용도로는 사용하더라도 무방하나, 특히 prod 환경에서는 절대 사용하지 말아야 하는 옵션입니다.
127.0.0.1:6379> scan 0 count 5
1) "114688"
2) 1) "b163919"
2) "e71056"
3) "e51232"
4) "b182485"
5) "c20095"
127.0.0.1:6379> scan 114688 count 15
1) "45056"
2) 1) "c5283"
2) "b31525"
3) "f176318"
4) "b157308"
5) "f51547"
6) "e35182"
7) "b103245"
8) "c101358"
9) "d187664"
10) "f178990"
11) "b162088"
12) "f68844"
13) "b3964"
14) "d84456"
15) "a77798"
127.0.0.1:6379>MATCH pattern (optional)
match 옵션을 통해 특정 key만 조회하는 것도 가능합니다.
특정 key를 count 만큼 습득하는 것이 아닌, count만큼의 key에서 패턴이 일치하는 것을 리턴하기 때문에 key가 조회되지 않을 수도 있습니다.
127.0.0.1:6379> scan 0 match 'a*'
1) "57344"
2) (empty list or set)
127.0.0.1:6379> scan 0 match 'c*'
1) "57344"
2) 1) "c20095"
2) "c5283"
127.0.0.1:6379> scan 0 match 'c*' count 20
1) "45056"
2) 1) "c20095"
2) "c5283"
3) "c101358"redis-cli --scan
single / sentinel redis
터미널 상에서 key를 조회할 때에는, redis-cli의 '--scan' 옵션을 통해 전탐색이 가능합니다.
이는 redis 에서 지원하는 것으로, cursor를 일일히 iterative하게 지정하지 않아주어도 전체를 탐색하게 해줍니다.
keys 와 같은 결과를 가지지만, 내부적으로 SCAN으로 동작하기 때문에 서비스에 장애에서 훨씬 안전합니다.
interpreter mode와 마찬가지로 pattern을 지정할 수 있지만, 그 사용법이 조금 다릅니다.
## redis-cli --help
## --scan List all keys using the SCAN command.
## --pattern <pat> Useful with --scan to specify a SCAN pattern.
## --count <count> SCAN with scan count.
redis-cli -p {port} --scan
redis-cli -p {port} --scan --pattern {pattern} --count {count}--scan --count
redis-cli --scan에서 SCAN count의 지정은 지원된지 얼마 되지 않았습니다.
redis 7.2 에서 새롭게 등장한 이 기능은 다량의 key를 가지고 있는 redis를 편히 scan하도록 도와줍니다.
하지만 7.2.4 버전까지의 이 기능에는 버그가 있어 의도대로 동작하지 않을 수 있습니다.
pattern이 명시되어 있지 않은 이상 count 옵션이 적용되지 않는 버그인데요, 만약 모든 key에 대해서 scan하고 싶다면 아래와 같이 사용할 필요가 있습니다.
redis-cli -p {port} --scan --pattern '*' --count {count}자세한 내용은 제가 직접 작성한 PR#13092을 참고해주세요.
추후 기회가 된다면 블로그 글로도 별도 작성하도록 하겠습니다.
(2024년 2월 28일자로, unstable redis에는 본 내용이 픽스되어 있습니다.)
cluster redis
클러스터의 경우에는 조금 다르게 접근해야합니다. 기본적으로 클러스터는 다수의 노드가 연결된 형태입니다.
single 혹은 sentinel 구성일 때와 동일하게 수행한다면, 타겟이 되는 하나의 노드의 key만 호출됩니다.
그렇기 때문에 우리는 각각의 shard에 대해서 scan을 수행할 필요가 있습니다.
cluster scan 명령어를 보기 전에 먼저, 테스트에 사용된 클러스터의 구성을 보도록 하겠습니다.
# 편의 상, ip 순으로 정렬합니다. (sort -k1)
# redis-cli --cluster info 127.0.0.1:6379 | sort -k1
73.24 keys per slot on average.
[OK] 1200001 keys in 12 masters.
127.0.0.1:6379 (########...) -> 99958 keys | 1365 slots | 1 slaves.
127.0.0.1:6380 (########...) -> 100004 keys | 1365 slots | 1 slaves.
127.0.0.1:6381 (########...) -> 100084 keys | 1366 slots | 1 slaves.
127.0.0.1:6382 (########...) -> 99940 keys | 1365 slots | 1 slaves.
127.0.0.2:6379 (########...) -> 100090 keys | 1366 slots | 1 slaves.
127.0.0.2:6380 (########...) -> 99995 keys | 1365 slots | 1 slaves.
127.0.0.2:6381 (########...) -> 100005 keys | 1365 slots | 1 slaves.
127.0.0.2:6382 (########...) -> 100062 keys | 1366 slots | 1 slaves.
127.0.0.3:6379 (########...) -> 99910 keys | 1365 slots | 1 slaves.
127.0.0.3:6380 (########...) -> 100014 keys | 1366 slots | 1 slaves.
127.0.0.3:6381 (########...) -> 99962 keys | 1365 slots | 1 slaves.
127.0.0.3:6382 (########...) -> 99977 keys | 1365 slots | 1 slaves.제가 테스트에 사용한 클러스터는 1,200,001개의 key를 가지며, 12개의 master와 12개의 slave로 구성되어 있습니다.
이제 각각의 ip:port pair에 대해 각각 --scan 명령어를 수행해주면 됩니다.
다행히, redis-cli 는 cluster nodes라는 명령어를 통해 클러스터의 다른 노드에 대한 정보를 취득할 수 있습니다.
해당 명령어는 master, slave 모두 리턴하기 때문에, slave의, ip부분만 필터링하도록 하겠습니다.
# 편의 상, ip 순으로 정렬합니다. (sort -k1)
# redis-cli -p 6379 cluster nodes | grep slave | awk '{print $2}' | awk -F @ '{print $1}' | sort -k1
127.0.0.1:6379
127.0.0.1:6380
127.0.0.1:6381
127.0.0.1:6382
127.0.0.2:6379
127.0.0.2:6380
127.0.0.2:6381
127.0.0.2:6382
127.0.0.3:6379
127.0.0.3:6380
127.0.0.3:6381
127.0.0.3:6382위의 info와 비교해보면, slave 정보가 잘 나온 것을 확인할 수 있습니다.
그럼 이제 key도 모두 조회가 되는지 확인해보기 위해, 위의 ip:port를 인자로 하여 --scan을 실행하겠습니다.
redis-cli -p 6379 cluster nodes | grep slave | grep -v noaddr | awk '{print $2}' | awk -F @ '{print $1}' | awk -F : '{print "-h "$1" -p "$2""}' | xargs -L 1 redis-cli --scan > cluster-full-scan.txt
키의 개수도 동일한 것을 확인할 수 있었으며, 내부에 있는 key도 정상적으로 파일로 출력된 것을 확인할 수 있습니다.
SCAN in client library
대다수의 사용자들이 terminal이 아닌 client library를 사용할 것입니다.
대부분의 client library는 다행스럽게도 'scan iterator'를 제공합니다.
scan cursor를 일일히 변수에 저장 후에 사용하지 않고, iterator의 기능을 활용하면 더욱 쉽게 SCAN 구현이 가능합니다.
이번 문단에서는 전체 redis에 대해서 원하는 key를 모두 탐색하는 방법에 대해서 다루겠습니다.
redis scan in python (redis-py)
redis-py: scan_iter
redis key scan은 python의 iterator를 이용해 더욱 간단하게 수행할 수 있습니다.
특히, 별도로 커서를 지정하지 않고 간단하게 작성할 수 있습니다.
cluster의 경우에도, redis connection을 cluster로서 진행하면 쉽게 scan이 가능합니다.
## pip install redis
import redis
# connect to redis
## single, sentinel mode
r = redis.Redis(host={hostname}, port={port}, password={password})
## cluster mode
r = redis.RedisCluster(host={hostname}, port={port}, password={password})
for key in r.scan_iter(match={pattern}, count={count}):
print(key)위의 예시 코드는 단순하게 패턴에 매칭되는 key를 출력하는 코드입니다.
for loop 안의 코드를 수정하는 것으로 특정 key를 삭제하거나 하는 등 추가적인 작업의 수행 또한 가능합니다.
cluster의 경우, 다른 shard의 데이터에 접근하기 위해 RedisCluster 함수를 이용해서 선언해주어야 합니다.
argparse를 이용한 python redis scanner 만들기
python의 argparse를 이용하면, redis-cli --scan과 유사하게 사용할 수 있습니다.
코드를 한 번 작성해두면, 매번 코드를 수정하지 않더라도 편하게 사용할 수 있습니다.
import redis
import argparse
def redisScan(host, port, password, match, count):
r = redis.Redis(host=host, port=port, password=password)
for key in r.scan_iter(match=match, count=count):
print(key)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--count', type=int, default=10, help='scan count')
parser.add_argument('--match', type=str, default='*', help='match pattern')
parser.add_argument('--host', type=str, default='127.0.0.1', help='redis host')
parser.add_argument('--port', type=int, default=6379, help='redis port')
parser.add_argument('--password', type=str, default='', help='redis password')
opt = parser.parse_args()
redisScan(opt.host, opt.port, opt.password, opt.match, opt.count)python3 keyscan.py # same as below command with options
python3 keyscan.py --host '127.0.0.1' --port 6379 --password '' --match '*' --count 10